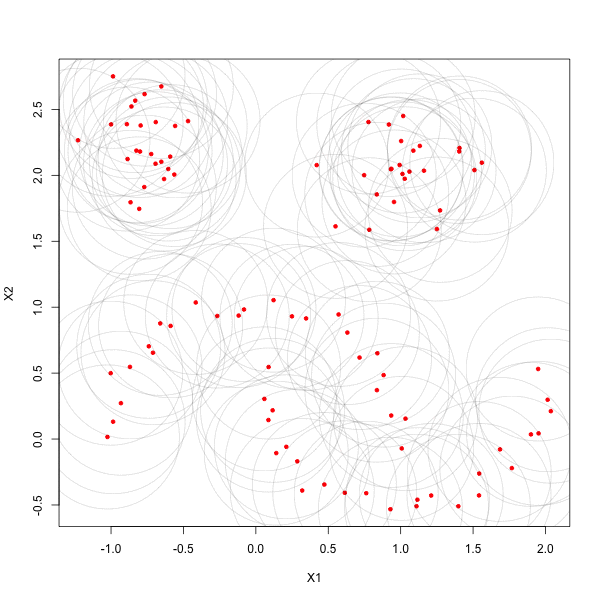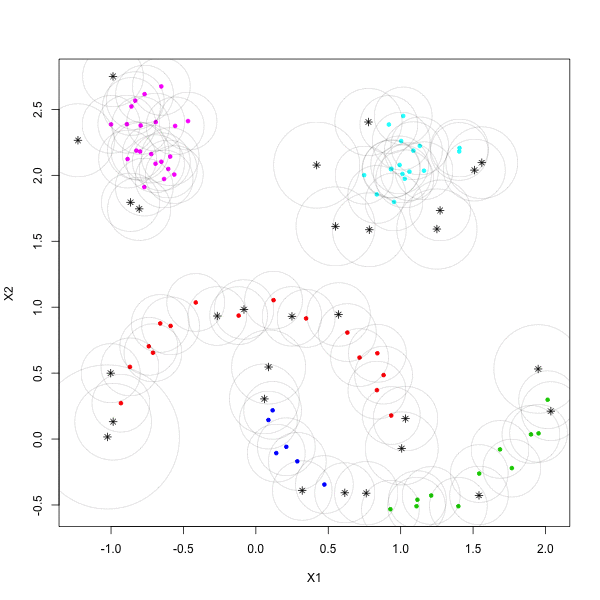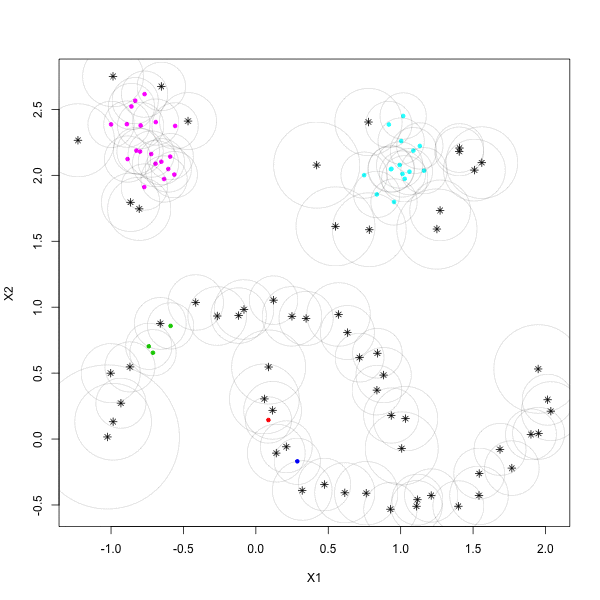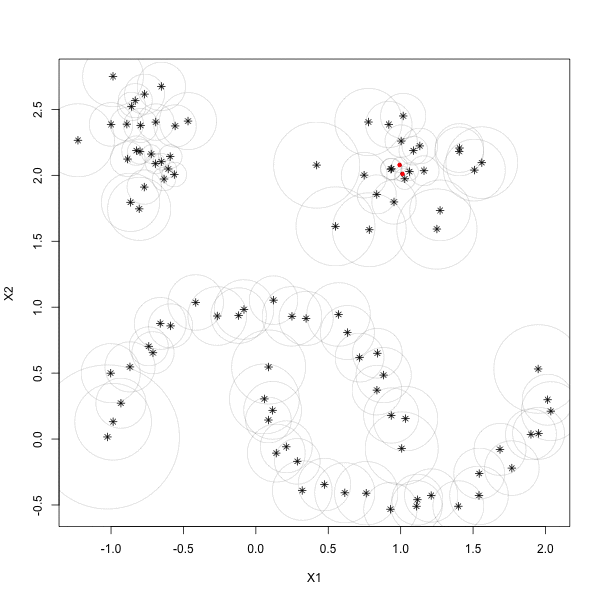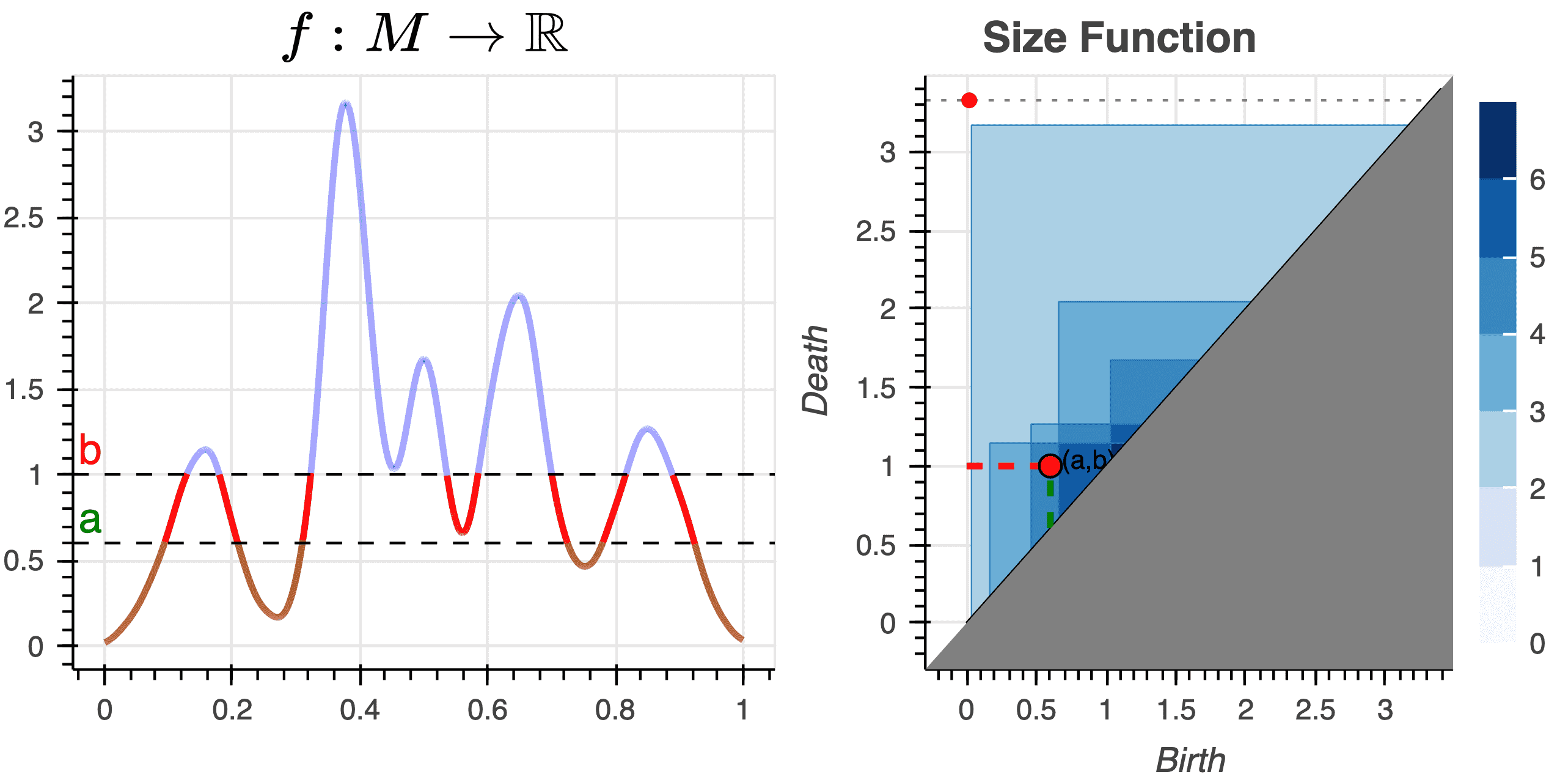
Using the fact that the persistent rank invariant determines the persistence diagram and vice versa, we introduce a framework for constructing families of continuous relaxations of the persistent rank invariant for persistence modules indexed over the real line. Like the rank invariant, these families obey inclusion-exclusion, are derived from simplicial boundary operators, and encode all the information needed to construct a persistence diagram. Unlike the rank invariant, these spectrally-derived families enjoy a number of stability and continuity properties typically reserved for persistence diagrams, such as smoothness and differentiability over the positive semi-definite cone. By leveraging its relationship with combinatorial Laplacian operators, we find the non-harmonic spectra of our proposed relaxation encode valuable geometric information about the underlying space, prompting several avenues for geometric data analysis. As these Laplacian operators are trace-class operators, we also find the corresponding relaxation can be efficiently approximated with a randomized algorithm based on the stochastic Lanczos quadrature method. We investigate the utility of our relaxation with applications in topological data analysis and machine learning, such as parameter optimization and shape classification.
M. Piekenbrock, J. A. Perea
Computational Persistence Workshop, 2023